20 Feb 2022
Categories:
Tags:
 Photo by Artem Gavrysh on UnsplashAs companies start to realise that Machine Learning has no value unless it is in production, new requirements start to rise — specially as the complexity of Machine Learning systems starts to increase as well.
Photo by Artem Gavrysh on UnsplashAs companies start to realise that Machine Learning has no value unless it is in production, new requirements start to rise — specially as the complexity of Machine Learning systems starts to increase as well.
At the same time, we are reaching a stage in AI & ML maturity where complex, cutting edge models are no longer the silver bullet for unlocking value out of data. Most practitioners in the field argue that most models can only be as good as the data that is used to train them. Andrew Ng describes this phenomena as the shift from Model Centric AI to Data Centric AI.
 Photo by Javier Allegue Barros on UnsplashThe urgency and opportunities that lie in Data Centric AI are also reinforced by Google, who concluded in a recent paper that data is the most under-valued and de-glamorised aspect of AI.
Photo by Javier Allegue Barros on UnsplashThe urgency and opportunities that lie in Data Centric AI are also reinforced by Google, who concluded in a recent paper that data is the most under-valued and de-glamorised aspect of AI.
“Paradoxically, data is the most under-valued and de-glamorised aspect of AI”
Feature Engineering
By now you might be aware that training Machine Learning models involves teaching it how to recognise common patterns in a training dataset. Once properly trained, a Machine Learning model should be able to correctly predict or infer labels or outcomes for unseen, or real-world data. In this context, feature engineering is paramount to extract the most possible value out of data.
Feature engineering can be understood as the process of uncovering these patterns in training data. Think about a fraud detection model, for instance. For a given training set containing customer credit card transactions, creating aggregated features based on customer spending behaviour (average monthly spend, for example) might be useful to uncover what had been previously implicit patterns. Thiscouldmake it easier for a model to distinguish fraudulent transactions from legit ones.
 Photo by Nadine Shaabana on Unsplash### Main Challenges with Feature Engineering
Photo by Nadine Shaabana on Unsplash### Main Challenges with Feature Engineering
While the example given above is quite simple, as use cases get more complex and data volumes increase, there are challenges associated with feature engineering.
- More scale means more complexity: as your data volume and size of your feature space grows, more efficiency and computing power are needed in order to process that data and train models in a timely fashion
- Reusability: features should be properly catalogued and their lineages should be known, so that it becomes simple to map, understand and reuse them across different use cases
- Feature hell: teams working in an independent, siloed fashion risk working in the same types of features, although each with different definitions and calculations. This is inefficient and impacts consistency across different models which consume the same set of features — and it also complicates the task of building upon existing features.
- Managing lifecycle: as time goes by, teams might find out that features are not useful anymore, or that feature definitions should be changed. Governance is also important: more often than not, teams want to limit who has access to each set of features, who changed feature definitions, and also why and when changes were performed.
- Audit & Interpretability: predictions generated by models might be challenged, disputed or audited. Having a good, clear track record of feature sets used by each model is important.
Feature Stores
The purpose of a Feature Store platform is to tackle this and other challenges that are common when doing feature engineering at scale. Having a solid Feature Store platform is paramount for achieving a good set of MLOps best practices. A common feature engineering and consumption lifecycle based on a feature store platform can be described by the diagram below.
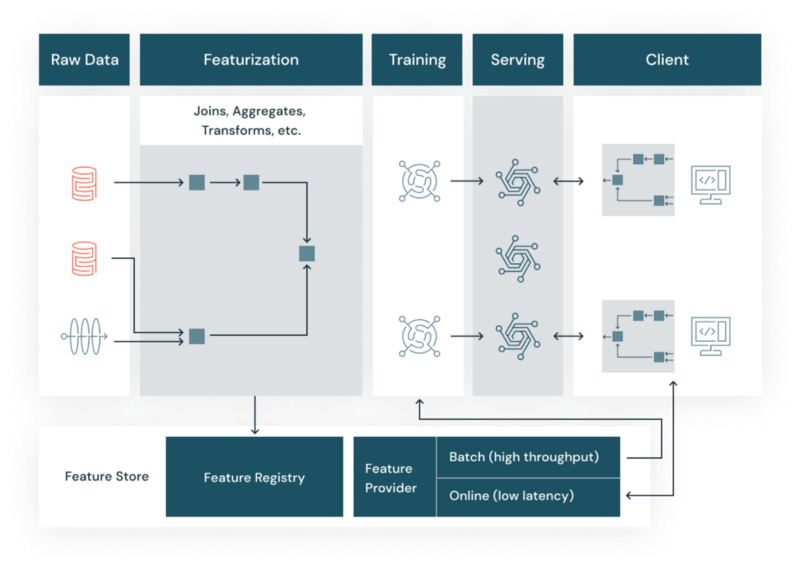 Source: Databricks### Existing Feature Store Offerings
Source: Databricks### Existing Feature Store Offerings
Currently there are many players who offer feature store platforms. Some examples include:
- Tecton: developed initially at Uber (Project Michelangelo), Tecton became a spin off company that offers a SaaS Feature Store platform. It is also available as an open source framework (Feast)
- Hopsworks: developed by Logical Clocks, Hopsworks is another offering which is available both as open source and SaaS product.
- Vertex AI Feature Store: Google Cloud Platform offering for Feature Store, supporting BigQuery and GCS data sources.
- Sagemaker Feature Store: AWS offering for Feature Store. Supports integration with S3, Athena and AWS Glue.
Being able to establish an accurate connection between feature set snapshots and different machine learning models is also important to guarantee that a machine learning system’s predictions are consistent, explainable and traceable. Apart from all feature engineering challenges, a good feature store platform should be easy to integrate with other MLOps platforms, such as MLflow.
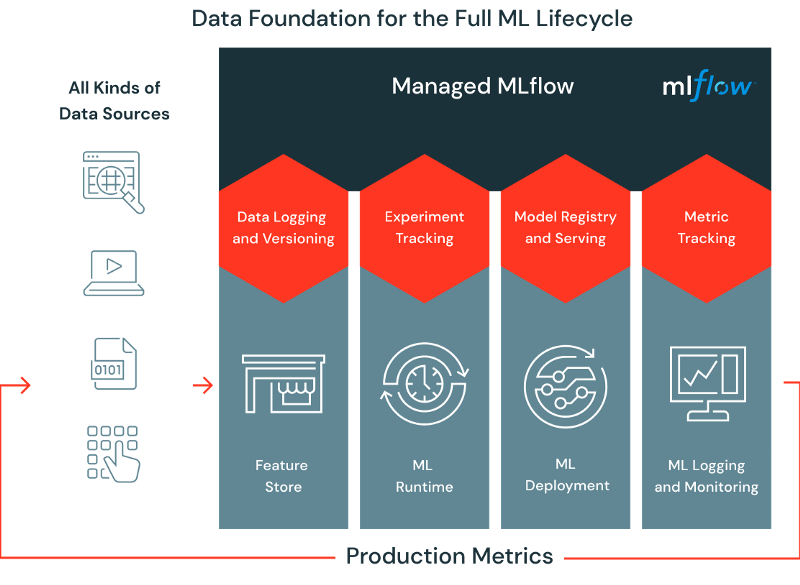 Source: DatabricksThis is one of the areas in which Databricks Feature Store shines. Being part of the Lakehouse ecosystem, Databricks Feature Store targets both batch and realtime use cases, having seamless integration with MLflow (also developed by Databricks). Having everything as part of a unified platform reduces the complexity and overhead associated with the overall Machine Learning architecture.
Source: DatabricksThis is one of the areas in which Databricks Feature Store shines. Being part of the Lakehouse ecosystem, Databricks Feature Store targets both batch and realtime use cases, having seamless integration with MLflow (also developed by Databricks). Having everything as part of a unified platform reduces the complexity and overhead associated with the overall Machine Learning architecture.
For more details about Feature Engineering, Databricks Feature Store and how to get started, you can refer to the links below. You can also create a free account on Databricks to take Feature Store and many other nice capabilities for a spin.
- Feature Engineering at Scale
- Use Case: Building a real-time Feature Store at IFood
- Databricks Feature Store Documentation
- Databricks Feature Store: Sample Notebook
You might also like these:
Keeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 1
Learn why Model Tracking and MLflow are critical for a successful machine learning projectmlopshowto.comKeeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 2
Learn how to use MLflow Model Registry to track, register and deploy Machine Learning Models effectively.mlopshowto.comAn Apache Airflow MVP: Complete Guide for a Basic Production Installation Using LocalExecutor
Simple and quick way to bootstrap Airflow in productionmlopshowto.com
16 Apr 2021
Categories:
Tags:
 ### The Case for Observability
### The Case for Observability
Google’s DevOps Research and Assessment (DORA) research states that a good enough monitoring and observability solution highly contributes to continuous delivery. Thus, it is natural that observability is a hot word today, specially in software engineering. It is within the interest of organisations developing software systems to continuously deliver value to end users.
When we talk about machine learning systems, it is not different. Evaluating the metrics of a Machine Learning system is obviously a critical task during research & development phase. However, once a machine learning model is deployed in production, it is also critical to know how this model is performing. Having good instrumentation and observability practices is needed, so that we can answer this question.
“Performing” in this case can mean different things — availability, quality and other aspects. Concretely, there are multiple possible metrics involved when trying to answer this question.
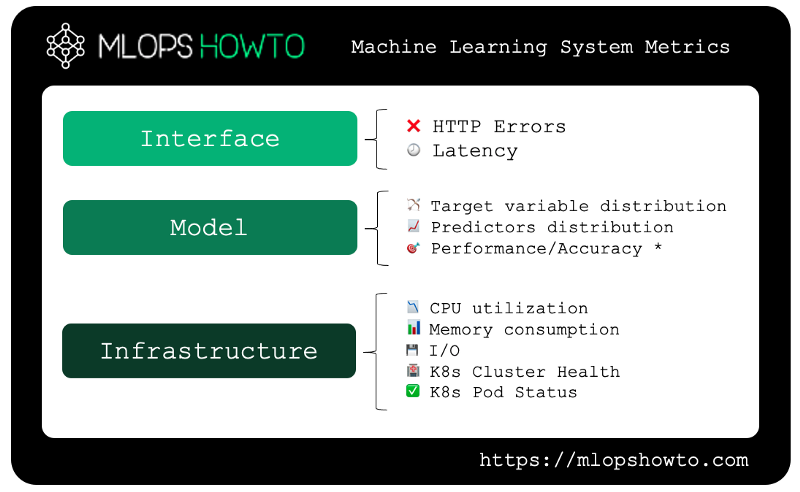 In the picture above, we can see the three main groups of metrics that we are interested when running a realtime Machine Learning system in production. Starting from the base and going through until the top of the pyramid, we have the following:
In the picture above, we can see the three main groups of metrics that we are interested when running a realtime Machine Learning system in production. Starting from the base and going through until the top of the pyramid, we have the following:
- Interface metrics: are our REST or GRPC API endpoints for our model available? If so, is the round-trip latency — the time between request and response — within acceptable boundaries?
- Model metrics: Has the statistical distribution of predicted values changed? Has the statistical distribution of our predictor variables changed? Does our model still have acceptable accuracy/error metrics?
- Infrastructure Metrics: Do we have enough compute resources (CPU/Memory)? Is our Kubernetes cluster healthy? Are our Pods available?
To gain some insights over these topics, we need to add some proper instrumentation to our setup. The good news are that in the Cloud Native world, there are well established tools to achieve that, namely Prometheus and Grafana.
In a nutshell, Prometheus is a platform for monitoring application metrics, while Grafana provides a platform to visualizing and generating alerts for these metrics. By making an analogy with an airplane, we can think of Prometheus as a set of sensors — monitoring speed, altitude, fuel and cabin pressure — while Grafana is the screen with multiple gauges, bells & whistles used to visualize the metrics associated with these measures, allowing to act upon them.
Implementation wise, both tools are modular, which allows for seamlessly connecting one to the other to export and define custom metrics, creating custom dashboards, configuring alerts, among other useful functionality.
Getting Started
We will work with the following setup:
Naturally, following along with other options such as kind, Minikube or an actual Kubernetes Cluster deployed in AWS, Azure or GCP is also possible.
To simplify our work, we will work with the kube-prometheus-stack Helm chart. It is a convenient way to install the full stack (Prometheus, Grafana and other dependencies) in one shot.
- Add Prometheus Helm Repo and Update Dependencies
First, we need to add a reference to the repo hosting the chart.
2. Install Kube Prometheus Stack Helm Chart
Now that our required repos have been configured and our dependencies have been updated, it’s time to install Prometheus into our cluster.
3. Check that everything is running
To check if the chart installation was successful, we can take a quick peak into the resources that are part of the monitoring namespace.
We should be able to see all the resources deployed in the monitoring namespace.
You might notice that there are some network services which are part of our installation. To access the Grafana interface, we will be interested in the prometheus-grafana one, which listens on port 80 by default. As part of the chart’s default configurations, it exposes the pod running the Grafana web interface through a ClusterIP service.
This means that to access the web interface for it, we need to do a port forward. We will listen on localhost port 3000, targeting port 80 of the network service.
Firing up our browser and hitting http://localhost:3000 should give us the Grafana web interface. After logging in with the default credentials — admin/prom-operator, we get the following:
 ### Visualizing Default Metric Dashboards
### Visualizing Default Metric Dashboards
Grafana comes with some default dashboards for monitoring a Kubernetes cluster. To visualize them, click on the “Manage” option under the Dashboards section on the left hand side menu.
For example, the Kubernetes / Compute Resources / Cluster dashboard will look like this:
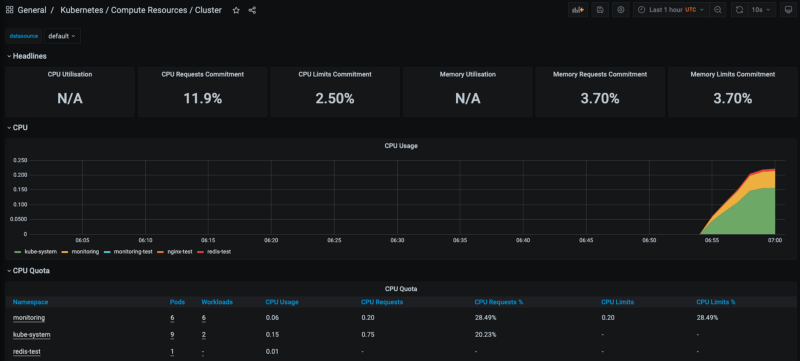 This is a pretty basic dashboard that shows some of the metrics in the Kubernetes cluster from a global perspective, considering all namespaces — CPU utilization, memory consumption, network requests, among others. If we click in any of the namespaces in the bottom, we are able to zoom into the metrics of that specific namespace.
This is a pretty basic dashboard that shows some of the metrics in the Kubernetes cluster from a global perspective, considering all namespaces — CPU utilization, memory consumption, network requests, among others. If we click in any of the namespaces in the bottom, we are able to zoom into the metrics of that specific namespace.
 Feel free to explore the other dashboards. Creating your own dashboard is also possible and quite straightforward.
Feel free to explore the other dashboards. Creating your own dashboard is also possible and quite straightforward.
Takeaways
Running a Microservices architecture in Kubernetes unlocks great benefits for deploying realtime Machine Learning Systems. However, to achieve success in that involves keeping track of how our machine learning systems are performing — not only in terms of accuracy metrics, but also in terms of availability, infrastructure, and so on.
In this context, it is clear that the Prometheus stack allows us to get a glimpse over the health of our machine learning systems from an infrastructure standpoint.
The great thing about this stack is that is is highly customisable: one can deploy different types of Prometheus metrics exporters across different Kubernetes namespaces, deployments and Pods. The same goes for Grafana — you can create your own dashboards, KPIs and alerts.
This is quite useful when we want to create more sophisticated monitoring mechanisms — such as interface and model metrics monitoring.
In our next post, we will continue exploring these capabilities.
In the meantime, you might want to check out:
Keeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 1
Learn why Model Tracking and MLflow are critical for a successful machine learning projectmlopshowto.comKeeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 2
Learn how to use MLflow Model Registry to track, register and deploy Machine Learning Models effectively.mlopshowto.comWhat is Model Drift, and How it Can Negatively Affect Your Machine Learning Investment
In the domains of software engineering and mission critical systems, we cannot say that monitoring and instrumentation…mlopshowto.comm
15 Mar 2021
Categories:
Tags:
 In the domains of software engineering and mission critical systems, we cannot say that monitoring and instrumentation is new, nor innovative — however, that does not mean that it is not an important discipline — specially as service level expectations get more and more critical.
In the domains of software engineering and mission critical systems, we cannot say that monitoring and instrumentation is new, nor innovative — however, that does not mean that it is not an important discipline — specially as service level expectations get more and more critical.
With machine learning systems, it is not different. Initially we can think that there is an obvious answer to why monitoring these systems is important, which is related to availability: we want to make sure that our machine learning models — delivered either as realtime prediction endpoints or batch workloads —are ready and available. To get an idea about how critical this is, just imagine the financial impact of an anti-fraud machine learning system from a bank or credit card issuer being offline for a few hours.
However, in machine learning systems, even if everything is apparently working — in other words, available — it can be the case that our predictions, which have been good for a while, start shifting away from the ground truth. Simply said, they start to become innacurate — our machine learning model is just not good as it used to be.
Model Drift
 Source: UnsplashImagine that you have an online bookstore, and you haven’t updated your machine learning model which generates users book recommendations for years. As you might imagine, you would not have an accurate picture of your customers — whose demographic variables and preferences might have changed over time. Not only that— you would not be recommending new books, since your recommendation system was not trained with them. In other words, it simply didn’t know about their existence.
Source: UnsplashImagine that you have an online bookstore, and you haven’t updated your machine learning model which generates users book recommendations for years. As you might imagine, you would not have an accurate picture of your customers — whose demographic variables and preferences might have changed over time. Not only that— you would not be recommending new books, since your recommendation system was not trained with them. In other words, it simply didn’t know about their existence.
In machine learning, this phenomena is known as model drift. While at principle more silent, this kind of issue can prove equally damaging financially — sometimes even more damaging than if our machine learning system is unavailable.
Types of Model Drift
There are many reasons why predictions made by a machine learning system can become innacurate. Model drift is one of them, and it can be due to multiple reasons.
Concept Drift
Concept drift happens when the statistical properties of our target variable change. For instance, a change in the distribution of the ground truth for a binary classification problem from 50/50 to 90/10. Another example happens when the meaning of a binary label changes —for instance, when you have credit default risk prediction model, and you decide to change the threshold used for classifying loans as delinquent. Or with an image classification problem, where you must classify plankton species — but at some point, a new species is discovered, and your model cannot correctly classify it.
Deep Blue Sea: Using Deep Learning to Detect Hundreds of Different Plankton Species
Unlocking the power of Keras, Transfer Learning and Ensemble Learning for contributing to the health of the world’s…towardsdatascience.com#### Data Drift
More common, data drift happens when the distribution or other statistical properties of our predictor variables changes — which makes our model bound to produce weird predictions. A customer churn prediction model that has been exclusively trained with data from before Covid 19 is a good example. Because of lockdown, most likely the statistical distribution of variables related to customer demographics and online behaviors have changed. As a result, your model would start showing poor results.
Monitoring, Detecting and Protecting from Model Drift
While there are multiple solutions to solve model drift, the first step is to detect it. To do that, we must monitor the behavior of our machine learning model in production. Once we have appropriate monitoring in place, we can assess relevant metrics from our model, and either act manually upon those, or conceptualize an automated course of action.
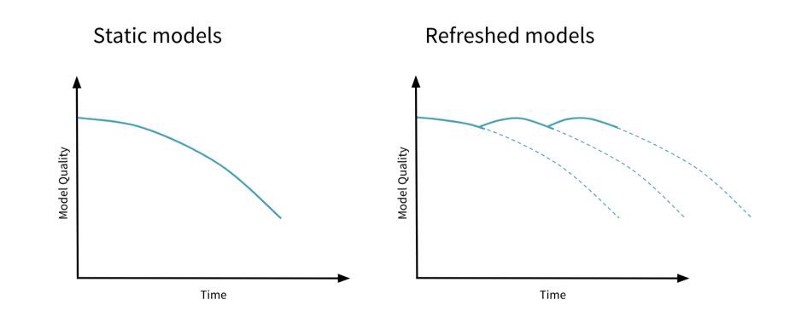 Model drift. Source: DatabricksAs we will demonstrate further in future posts, a simple way to solve model drift is by retraining our models. By ensuring that our models are always fresh — trained with sufficiently recent and accurate data — we can mitigate the risk that it will run into model drift. This way we guarantee that the investment made in design and implementation phases of our machine learning lifecycle continue to generate the expected value.
Model drift. Source: DatabricksAs we will demonstrate further in future posts, a simple way to solve model drift is by retraining our models. By ensuring that our models are always fresh — trained with sufficiently recent and accurate data — we can mitigate the risk that it will run into model drift. This way we guarantee that the investment made in design and implementation phases of our machine learning lifecycle continue to generate the expected value.
There are many approaches and frameworks to implement metrics monitoring and model drift detection for machine learning systems. When it comes to the cloud native world, a stack composed by tools such as Prometheus, Grafana and MLFlow is frequently used for that purpose, and the great thing is that running these in a Kubernetes cluster is really straightforward — which will surely be the topic for another post.
Keeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 2
Learn how to use MLflow Model Registry to track, register and deploy Machine Learning Models effectively.mlopshowto.comWhat is Kubernetes and Why it is so Important for Machine Learning Engineering and MLOps
If you follow up technology trends, data science, artificial intelligence and machine learning, chances are that you…mlopshowto.comA Journey Into Machine Learning Observability with Prometheus and Grafana, Part I
Deploying Prometheus and Grafana on Kubernetes in 10 minutes for basic infrastructure monitoringmlopshowto.com
14 Mar 2021
Categories:
Tags:
 Source: UnsplashIf you follow up technology trends, data science, artificial intelligence and machine learning, chances are that you have come across with the term Kubernetes (or K8s, its geek nickname).
Source: UnsplashIf you follow up technology trends, data science, artificial intelligence and machine learning, chances are that you have come across with the term Kubernetes (or K8s, its geek nickname).
Created by Google, Kubernetes is an open source container orchestration platform. The name “Kubernetes” comes from the greek language, meaning “helmsman” or “captain”. But before understanding the reason for all these nautical references, we first need to address the question: what are containers?
Why do we need containers
 Source: UnsplashContainers exploded in 2013 with the creation of Docker. Their creation was motivated by a longstanding issue in software engineering: how to get software to run reliably when moved from one environment to another. Such environments could range from anything from laptops, bare metal servers sitting in a good old private data center or virtual machines in the cloud. Packaging an application into a container means that the end result of running it across any of these environments will be consistent.
Source: UnsplashContainers exploded in 2013 with the creation of Docker. Their creation was motivated by a longstanding issue in software engineering: how to get software to run reliably when moved from one environment to another. Such environments could range from anything from laptops, bare metal servers sitting in a good old private data center or virtual machines in the cloud. Packaging an application into a container means that the end result of running it across any of these environments will be consistent.
This is specially critical as technology organizations shift away from monolithic architecture patterns, such as service oriented architecture (SOA), to more loosely coupled, microservices based approaches such as service mesh — which in itself are good candidates for another article.
The need for container orchestrators
Containers solve a large part of the issue, but they are not enough, in that they are more of an abstraction. To get a working product, we still need a container runtime — an additional layer to coordinate and allocate proper resources to running containers. To solve that problem, the folks at Docker created containerd, a container runtime.
“Why not use containerd, then?”— you might rightfully ask.Yes, you could simply spin up a virtual machine and use Docker or Docker Compose to run one or more different containers.Well, the challenge here is that as application architectures become more complex, we need to manage things such as:
- Reliability: our application needs to meet performance standards and yield correct output for a specific time
- Availability: our application should be operationally available for the desired percentage of the time
- Scalability: should be possible to seamlessly scale depending on the workload — preferably in an automated fashion
- Continuous Deployment: we want to deploy our changes to production in a fast, continuous way, without disrupting existing deployments.
This is where Kubernetes comes in.
Meet the Helmsman
 Source: UnsplashImagine that we have a transportation business in the Port of Rotterdam, and we must routinely ship multiple containers to Port of Southampton, in the United Kingdom. One way to do it would be using a simple, small ship that which is able to carry a couple of containers. It is able to move fast and take these containers from Rotterdam in a seamless fashion. However, it has the following caveats:
Source: UnsplashImagine that we have a transportation business in the Port of Rotterdam, and we must routinely ship multiple containers to Port of Southampton, in the United Kingdom. One way to do it would be using a simple, small ship that which is able to carry a couple of containers. It is able to move fast and take these containers from Rotterdam in a seamless fashion. However, it has the following caveats:
- It has low autonomy— you spend more time refuelling
- Higher chance to sink — along with the containers
- Low scale — It can only carry two containers at a time
If we instead decide to leverage an bigger, full fledged cargo ship to move our containers from Rotterdam to Southampton, we can do it in a much more reliable, scalable way:
- High autonomy— less time spent refuelling
- Less likely to sink
- High scale — Can carry hundreds of containers at once
In this basic example we can picture a simple container runtime as a the small ship, and Kubernetes as a full fledged cargo ship. It was created by Google with a basic feature set in mind:
- Replication —to deploy multiple instances of an application
- Load balancing and service discovery —to route traffic to these replicated containers
- Basic health checking and repair —to ensure a self-healing system
- Scheduling —to group many machines into a single pool and distribute work to them
The combination of these features also makes it possible to leverage some bonus aspects. Being able to easily replicate application instances also eases the task of deploying application versions without any kind of disruption — which enables for continuous deploymentand more agile practices.
And that’s not all. By leveraging Kubernetes manifests’ declarative approach for creating resources within the cluster, we are paving the way for, amongst other things, enabling self-service architectures where data engineers, data scientists and users in general can provision their own infrastructure with very low (human) effort.
Why Kubernetes Is So Important for Machine Learning and MLOps
 Source: UnsplashRecently, companies have started realising that in machine learning, research and development plays a huge part. But if not enough time, budget and effort is spent in properly designing and deploying machine learning systems in a reliable, available, discoverable and efficient manner, it becomes challenging to reap all of its benefits.
Source: UnsplashRecently, companies have started realising that in machine learning, research and development plays a huge part. But if not enough time, budget and effort is spent in properly designing and deploying machine learning systems in a reliable, available, discoverable and efficient manner, it becomes challenging to reap all of its benefits.
Keeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 2
Learn how to use MLflow Model Registry to track, register and deploy Machine Learning Models effectively.mlopshowto.comKeeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 1
Learn why Model Tracking and MLflow are critical for a successful machine learning projectmlopshowto.comAbout MLOps And Why Most Machine Learning Projects Fail — Part 1
If you have been involved with Machine Learning (or you are aiming to be), you might be aware that reaping the…mlopshowto.comBy thinking of machine learning systems with an engineering mindset, it becomes clear that Kubernetes is a good match to achieve the aforementioned reliability, availability and time-to-market challenges. Kubernetes helps adopting the main principles of MLOps, and by doing that we are increasing the chances that our machine learning systems will provide the expected value after all the investment made in the research, development and design steps.
Finally, there is also a secondary aspect which is related to the current MLOps ecosystem which builds upon Kubernetes — with existing tools and frameworks such as Kubeflow, Pachyderm, ArgoandSeldonhaving been created to address common MLOps challenges as examples.
Like with everything in life, it is not all fun and games
Conceptualizing and implementing a Kubernetes architecture does not happen from one day to the other, and managing Kubernetes clusters comes with additional responsibilities, namely in terms of governance, security, support, maintenance and costs —critical components which are also good topics for a next article.
03 Mar 2021
Categories:
Tags:
 If you have been involved with Machine Learning (or you are aiming to be), you might be aware that reaping the benefits of Machine Learning systems in real life is not a trivial task.
If you have been involved with Machine Learning (or you are aiming to be), you might be aware that reaping the benefits of Machine Learning systems in real life is not a trivial task.
Well, if that is indeed the case, there are some good news — you and your company would certainly not be alone. According to Gartner, “Through 2020, 80% of AI projects will remain alchemy, run by wizards whose talents will not scale in the organization”. A similar estimation by VentureBeat claims that a whopping 87% of AI projects will never make it into production. With more and more money being poured over Machine Learning projects, that is certainly an alarming metric.
Let’s quantify this a bit. In 2019 alone, approximately USD 40 billions were invested into privately held AI companies. If we extrapolate this and throw the approximated success rate of AI projects into these figures (and completely exclude intracompany ML investments), we reach the conclusion that in 2019, around USD 38 billions were wasted due to unsuccessful Machine Learning projects.
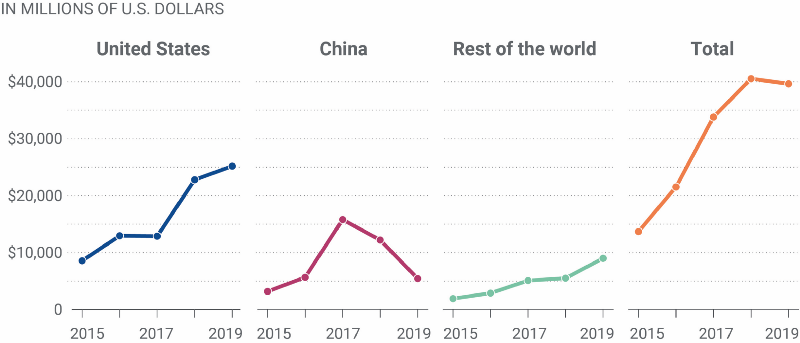 Figure 1: Total disclosed value of equity investments in privately held AI companies, by target region. Source: Brookings Tech StreamApart from the — quite significant — economic problem, that brings additional issues. Pressure mounts into existing and new ML projects and initiatives, and skepticism within the industry tends to grow. This results in a vicious circle —skepticism leads to less investments, which leads to less potential for scale; consequently, tangible benefits associated with Machine Learning projects start to wane.It becomes harder and harder to justify investment in these initiatives.
Figure 1: Total disclosed value of equity investments in privately held AI companies, by target region. Source: Brookings Tech StreamApart from the — quite significant — economic problem, that brings additional issues. Pressure mounts into existing and new ML projects and initiatives, and skepticism within the industry tends to grow. This results in a vicious circle —skepticism leads to less investments, which leads to less potential for scale; consequently, tangible benefits associated with Machine Learning projects start to wane.It becomes harder and harder to justify investment in these initiatives.
But why is it so difficult? After all — data science, machine learning, statistics— we are talking about exact sciences, aren’t we? Shouldn’t this type of projects and investments be more predictable (no pun intended)?
The Sexiest Job of the 21st Century
One of the issues is that Machine Learning is currently seen as a gold rush. There are many reasons for this phenomena — hype is certainly one of them. You might remember the infamous article from Harvard Business Review, who in 2021 positioned the data scientist as “the sexiest job of the 21st century”.
What was seen after that was the following:
- There was (and still is) an avalanche of people wanting to jump into data science (without having the skills)
- There was (and still is) and avalanche of companies wanting to jump into data science (without having the experience)
- The amount of data generated worldwide has grown to colossal proportions — but not a lot of this data has immediate business value, even when cutting edge machine learning techniques come into play. This is where adequate data governance and data engineering planning are key.
- There were (and still are) many activities inherent to productionizing machine learning models which are still being overlooked — both by companies and wannabe data scientists & machine learning practitioners
Here, a parenthesis is needed: there are many companies and public cloud providers excelling in the data governance and engineering space — perhaps due to the fact that these disciplines are also key for success in good old business intelligence. However, the same cannot be said about the latter item.
People are desperate to get into data science, companies are desperate to get into data science, but the bulk of what is being produced are Machine Learning models which never make it into Production and end up in the twilight zone of Jupyter Notebooks.
 What was once a cutting edge ML model. Source: Ante Hamersmit / Unsplash### Looking for Answers
What was once a cutting edge ML model. Source: Ante Hamersmit / Unsplash### Looking for Answers
While HBR’s infamous article was published in 2012; it took around two years for another landmark article to see the light of day. In “Machine Learning: The High Interest Credit Card of Technical Debt (2014)”, researchers from Google claimed:
(…) we note that it is remarkably easy to incur massive ongoing maintenance costs at the system level when applying machine learning. The goal of this paper is highlight several machine learning specific risk factors and design patterns to be avoided or refactored where possible. These include boundary erosion, entanglement, hidden feedback loops, undeclared consumers, data dependencies, changes in the external world, and a variety of system-level anti-patterns.
It was the first time someone raised the importance of thinking about machine learning productionization as a discipline in itself — at least in the tech mainstream.
What is Kubernetes and Why it is so Important for Machine Learning Engineering and MLOps
If you follow up technology trends, data science, artificial intelligence and machine learning, chances are that you…mlopshowto.com### A Blast from the Past
Looking at the most critical aspects mentioned by Google Researchers, one might see an overlap with another science that has been around for quite a while. A discipline that has allowed for immense innovation in the form of things that are part of our daily lives, from airspace controlling to social networks, electronic bank transactions and whatnot. Yes, I am talking about Software Engineering.
 Source: UnsplashMachine Learning has already been part of any CS curriculum for at least 50 years. That brings us a follow up question — why has it taken so long for us in the ML industry to connect the dots and leverage software engineering best practices?
Source: UnsplashMachine Learning has already been part of any CS curriculum for at least 50 years. That brings us a follow up question — why has it taken so long for us in the ML industry to connect the dots and leverage software engineering best practices?
The answer might be in the fact that besides being around for many years, software engineering practices have changed dramatically in recent years, specially with the advent of Agile and DevOps. Which are proving to be key concepts in productionizing machine learning systems and thus increasing its business potential.
 MLOps cycle. Source: ml-ops.orgCompanies such as Deep Learning startup Paperspace have been pointing at the issues in this topic in a more concrete fashion:
MLOps cycle. Source: ml-ops.orgCompanies such as Deep Learning startup Paperspace have been pointing at the issues in this topic in a more concrete fashion:
Here are a few examples: an absurd amount of work happens on siloed desktop computers (even to this day); there’s practically zero automation (e.g. automated tests); collaboration is a mess; pipelines are hacked together with a constellation of home-rolled and brittle scripts; visibility is practically non-existent when it comes to models deployed to development, staging, and production; CI/CD is a foreign concept; model versioning is difficult for many organizations to even define; rigorous health and performance monitoring of models is extremely rare, and the list goes on.
This is where Machine Learning Operations (MLOps) comes to the rescue. MLOps borrows concepts from DevOps, such as Continuous Delivery (CD), while adding new concepts, such as Continuous Training (CT), Monitoring and Observability.
A Journey Into Machine Learning Observability with Prometheus and Grafana, Part I
Deploying Prometheus and Grafana on Kubernetes in 10 minutes for basic infrastructure monitoringmlopshowto.comThere are other disciplines which while not exactly related to MLOps, play equal importance, such as fairness, explainability, scalability, performance, security and integrity. Besides not being directly related to machine learning systems output, it becomes clear that these concepts become more and more important as machine learning systems and applications evolve.
This is where we come to the purpose of this website. We will cover not only the what and the why of MLOps, but most importantly the how — not only from a conceptual perspective, which is important, but also from the practical side.
