
What are Feature Stores and Why Are They Critical For Scaling Machine Learning
20 Feb 2022
At the same time, we are reaching a stage in AI & ML maturity where complex, cutting edge models are no longer the silver bullet for unlocking value out of data. Most practitioners in the field argue that most models can only be as good as the data that is used to train them. Andrew Ng describes this phenomena as the shift from Model Centric AI to Data Centric AI.

“Paradoxically, data is the most under-valued and de-glamorised aspect of AI”
Feature Engineering
By now you might be aware that training Machine Learning models involves teaching it how to recognise common patterns in a training dataset. Once properly trained, a Machine Learning model should be able to correctly predict or infer labels or outcomes for unseen, or real-world data. In this context, feature engineering is paramount to extract the most possible value out of data.
Feature engineering can be understood as the process of uncovering these patterns in training data. Think about a fraud detection model, for instance. For a given training set containing customer credit card transactions, creating aggregated features based on customer spending behaviour (average monthly spend, for example) might be useful to uncover what had been previously implicit patterns. Thiscouldmake it easier for a model to distinguish fraudulent transactions from legit ones.

While the example given above is quite simple, as use cases get more complex and data volumes increase, there are challenges associated with feature engineering.
- More scale means more complexity: as your data volume and size of your feature space grows, more efficiency and computing power are needed in order to process that data and train models in a timely fashion
- Reusability: features should be properly catalogued and their lineages should be known, so that it becomes simple to map, understand and reuse them across different use cases
- Feature hell: teams working in an independent, siloed fashion risk working in the same types of features, although each with different definitions and calculations. This is inefficient and impacts consistency across different models which consume the same set of features — and it also complicates the task of building upon existing features.
- Managing lifecycle: as time goes by, teams might find out that features are not useful anymore, or that feature definitions should be changed. Governance is also important: more often than not, teams want to limit who has access to each set of features, who changed feature definitions, and also why and when changes were performed.
- Audit & Interpretability: predictions generated by models might be challenged, disputed or audited. Having a good, clear track record of feature sets used by each model is important.
Feature Stores
The purpose of a Feature Store platform is to tackle this and other challenges that are common when doing feature engineering at scale. Having a solid Feature Store platform is paramount for achieving a good set of MLOps best practices. A common feature engineering and consumption lifecycle based on a feature store platform can be described by the diagram below.
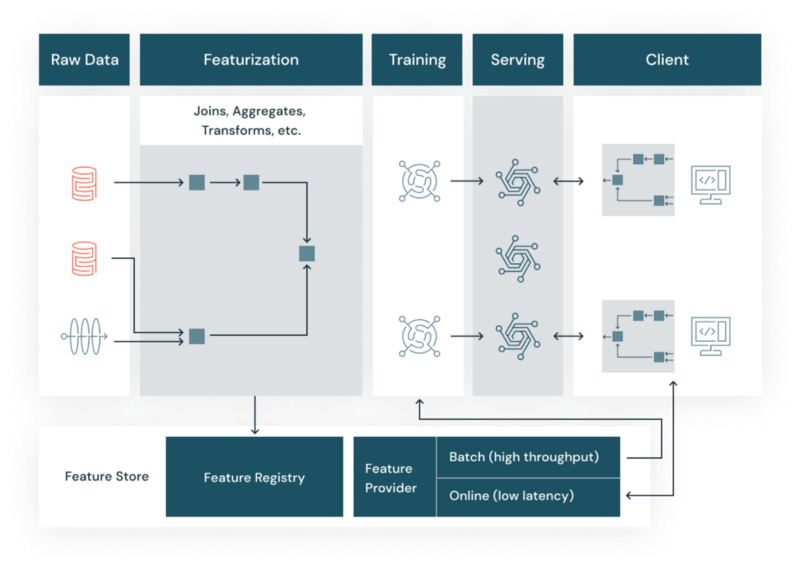 Source: Databricks### Existing Feature Store Offerings
Source: Databricks### Existing Feature Store Offerings
Currently there are many players who offer feature store platforms. Some examples include:
- Tecton: developed initially at Uber (Project Michelangelo), Tecton became a spin off company that offers a SaaS Feature Store platform. It is also available as an open source framework (Feast)
- Hopsworks: developed by Logical Clocks, Hopsworks is another offering which is available both as open source and SaaS product.
- Vertex AI Feature Store: Google Cloud Platform offering for Feature Store, supporting BigQuery and GCS data sources.
- Sagemaker Feature Store: AWS offering for Feature Store. Supports integration with S3, Athena and AWS Glue.
Being able to establish an accurate connection between feature set snapshots and different machine learning models is also important to guarantee that a machine learning system’s predictions are consistent, explainable and traceable. Apart from all feature engineering challenges, a good feature store platform should be easy to integrate with other MLOps platforms, such as MLflow.
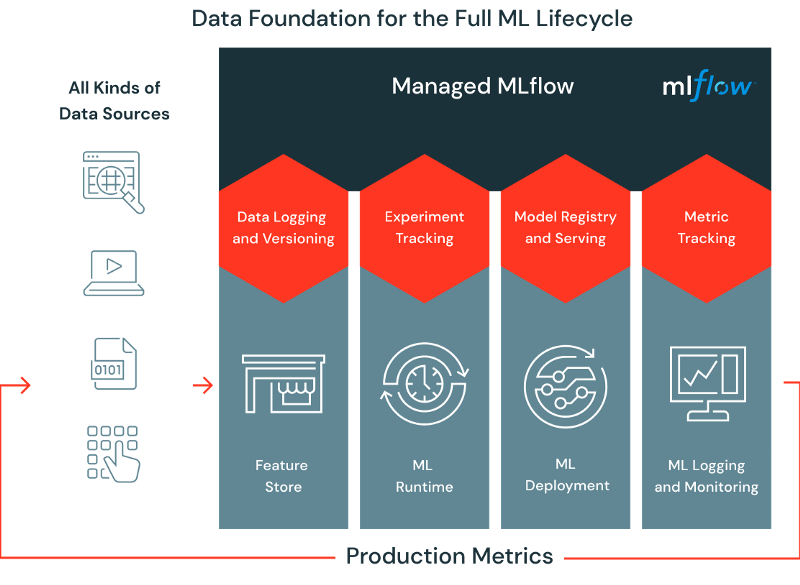 Source: DatabricksThis is one of the areas in which Databricks Feature Store shines. Being part of the Lakehouse ecosystem, Databricks Feature Store targets both batch and realtime use cases, having seamless integration with MLflow (also developed by Databricks). Having everything as part of a unified platform reduces the complexity and overhead associated with the overall Machine Learning architecture.
Source: DatabricksThis is one of the areas in which Databricks Feature Store shines. Being part of the Lakehouse ecosystem, Databricks Feature Store targets both batch and realtime use cases, having seamless integration with MLflow (also developed by Databricks). Having everything as part of a unified platform reduces the complexity and overhead associated with the overall Machine Learning architecture.
For more details about Feature Engineering, Databricks Feature Store and how to get started, you can refer to the links below. You can also create a free account on Databricks to take Feature Store and many other nice capabilities for a spin.
- Feature Engineering at Scale
- Use Case: Building a real-time Feature Store at IFood
- Databricks Feature Store Documentation
- Databricks Feature Store: Sample Notebook
You might also like these:
Keeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 1
Learn why Model Tracking and MLflow are critical for a successful machine learning projectmlopshowto.comKeeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 2
Learn how to use MLflow Model Registry to track, register and deploy Machine Learning Models effectively.mlopshowto.comAn Apache Airflow MVP: Complete Guide for a Basic Production Installation Using LocalExecutor
Simple and quick way to bootstrap Airflow in productionmlopshowto.com