
What is Model Drift, and How it Can Negatively Affect Your Machine Learning Investment
15 Mar 2021 In the domains of software engineering and mission critical systems, we cannot say that monitoring and instrumentation is new, nor innovative — however, that does not mean that it is not an important discipline — specially as service level expectations get more and more critical.
In the domains of software engineering and mission critical systems, we cannot say that monitoring and instrumentation is new, nor innovative — however, that does not mean that it is not an important discipline — specially as service level expectations get more and more critical.
With machine learning systems, it is not different. Initially we can think that there is an obvious answer to why monitoring these systems is important, which is related to availability: we want to make sure that our machine learning models — delivered either as realtime prediction endpoints or batch workloads —are ready and available. To get an idea about how critical this is, just imagine the financial impact of an anti-fraud machine learning system from a bank or credit card issuer being offline for a few hours.
However, in machine learning systems, even if everything is apparently working — in other words, available — it can be the case that our predictions, which have been good for a while, start shifting away from the ground truth. Simply said, they start to become innacurate — our machine learning model is just not good as it used to be.
Model Drift
 Source: UnsplashImagine that you have an online bookstore, and you haven’t updated your machine learning model which generates users book recommendations for years. As you might imagine, you would not have an accurate picture of your customers — whose demographic variables and preferences might have changed over time. Not only that— you would not be recommending new books, since your recommendation system was not trained with them. In other words, it simply didn’t know about their existence.
Source: UnsplashImagine that you have an online bookstore, and you haven’t updated your machine learning model which generates users book recommendations for years. As you might imagine, you would not have an accurate picture of your customers — whose demographic variables and preferences might have changed over time. Not only that— you would not be recommending new books, since your recommendation system was not trained with them. In other words, it simply didn’t know about their existence.
In machine learning, this phenomena is known as model drift. While at principle more silent, this kind of issue can prove equally damaging financially — sometimes even more damaging than if our machine learning system is unavailable.
Types of Model Drift
There are many reasons why predictions made by a machine learning system can become innacurate. Model drift is one of them, and it can be due to multiple reasons.
Concept Drift
Concept drift happens when the statistical properties of our target variable change. For instance, a change in the distribution of the ground truth for a binary classification problem from 50/50 to 90/10. Another example happens when the meaning of a binary label changes —for instance, when you have credit default risk prediction model, and you decide to change the threshold used for classifying loans as delinquent. Or with an image classification problem, where you must classify plankton species — but at some point, a new species is discovered, and your model cannot correctly classify it.
More common, data drift happens when the distribution or other statistical properties of our predictor variables changes — which makes our model bound to produce weird predictions. A customer churn prediction model that has been exclusively trained with data from before Covid 19 is a good example. Because of lockdown, most likely the statistical distribution of variables related to customer demographics and online behaviors have changed. As a result, your model would start showing poor results.
Monitoring, Detecting and Protecting from Model Drift
While there are multiple solutions to solve model drift, the first step is to detect it. To do that, we must monitor the behavior of our machine learning model in production. Once we have appropriate monitoring in place, we can assess relevant metrics from our model, and either act manually upon those, or conceptualize an automated course of action.
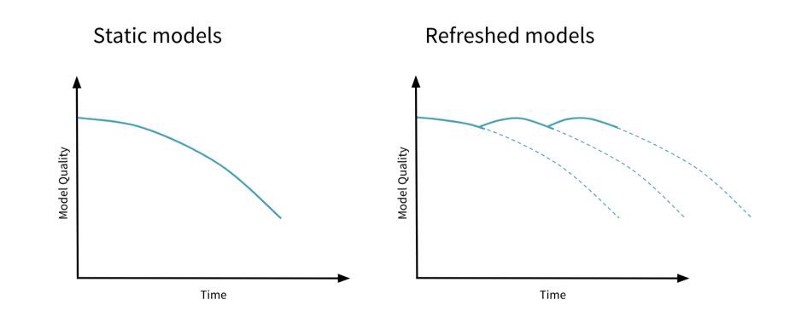 Model drift. Source: DatabricksAs we will demonstrate further in future posts, a simple way to solve model drift is by retraining our models. By ensuring that our models are always fresh — trained with sufficiently recent and accurate data — we can mitigate the risk that it will run into model drift. This way we guarantee that the investment made in design and implementation phases of our machine learning lifecycle continue to generate the expected value.
Model drift. Source: DatabricksAs we will demonstrate further in future posts, a simple way to solve model drift is by retraining our models. By ensuring that our models are always fresh — trained with sufficiently recent and accurate data — we can mitigate the risk that it will run into model drift. This way we guarantee that the investment made in design and implementation phases of our machine learning lifecycle continue to generate the expected value.
There are many approaches and frameworks to implement metrics monitoring and model drift detection for machine learning systems. When it comes to the cloud native world, a stack composed by tools such as Prometheus, Grafana and MLFlow is frequently used for that purpose, and the great thing is that running these in a Kubernetes cluster is really straightforward — which will surely be the topic for another post.
Keeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 2
Learn how to use MLflow Model Registry to track, register and deploy Machine Learning Models effectively.mlopshowto.comWhat is Kubernetes and Why it is so Important for Machine Learning Engineering and MLOps
If you follow up technology trends, data science, artificial intelligence and machine learning, chances are that you…mlopshowto.comA Journey Into Machine Learning Observability with Prometheus and Grafana, Part I
Deploying Prometheus and Grafana on Kubernetes in 10 minutes for basic infrastructure monitoringmlopshowto.com