
Keeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 1
30 Apr 2022
You cannot understand what is happening today without understanding what came before (Steve Jobs)
Machine Learning as an Empirical Science — and the importance of experiment tracking
 Empirical research is an evidence-based approach to the study and interpretation of information. The empirical approach relies on real-world data, metrics and results rather than theories and concepts. Empiricism is the idea that knowledge is primarily received through experience and attained through the five senses.
Empirical research is an evidence-based approach to the study and interpretation of information. The empirical approach relies on real-world data, metrics and results rather than theories and concepts. Empiricism is the idea that knowledge is primarily received through experience and attained through the five senses.
Machine Learning has both theoretical and empirical aspects. While theory and concepts are extremely important, they are not enough to achieve our objectives and validate our hypothesis —since most learning algorithms are too complex for formal analysis. Experimentation is also a critical part of machine learning.
In order to validate our initial hypothesis, we work with the assumption that our experiments are sufficiently robust and successful. As a byproduct, we would end up with a model which is able to predict outcomes for previously unseen events, based on the data which was used for training.
Of course, reality is much more nuanced, complex — and less linear— than that. More often than not we will need to test many different hypothesis, until we find one that while not bad, is mediocre at best. Many iterations later, we might end up with a satisfactory model.
The case for Machine Learning Model Tracking
Being able to look back into different machine learning experiments, their inputs, parameters and outcomes is critical in order to iteratively improve our models and increase our chances of success.
One reason for this is that the cutting edge model that you spent days training last week might be no longer good enough today. In order to detect and conclude that, information about the inputs, metrics and the code related to that model must be available somewhere.
This is where many people might say — I’m already tracking this. And my hundred Jupyter Notebooks can prove that. Others might say something similar, while replacing Jupyter Notebooks with Excel Spreadsheets.
 How a folder full of different Jupyter Notebooks looks likeWhile none of these approaches is inherently wrong, the process gets challenging and error-prone once you start to move along three scales:
How a folder full of different Jupyter Notebooks looks likeWhile none of these approaches is inherently wrong, the process gets challenging and error-prone once you start to move along three scales:
- Number of use cases and models;
- Scale of your team;
- Variety of your models (and data)
In other words, you do not want to rely on Jupyter Notebooks and Excel spreadsheets when you are running production grade machine learning systems — you need something structured and flexible, which enables seamless collaboration amongst different people and personas.
Introducing MLflow
 MLflow is an open source project that was created by Databricks — the same company behind Apache Spark and Delta, amazing open source projects as well.
MLflow is an open source project that was created by Databricks — the same company behind Apache Spark and Delta, amazing open source projects as well.
The main objective of MLflow is to provide a unified platform for enabling collaboration across different teams involved in creating and deploying machine learning systems, such as data scientists, data engineers and machine learning engineers.
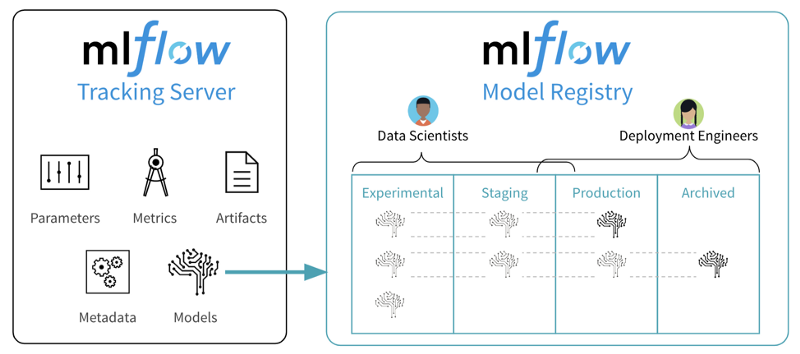 A typical Machine Learning workflow using MLflowIn terms of functionalities, MLflow allows tracking Machine Learning experiments in a seamless way, while also providing a single source of truth for model artifacts. It has native support for a wide variety of model flavors— think plain vanilla Sci-Kit Learn, but also models trained with R, SparkML, Tensorflow, Pytorch, amongst others.
A typical Machine Learning workflow using MLflowIn terms of functionalities, MLflow allows tracking Machine Learning experiments in a seamless way, while also providing a single source of truth for model artifacts. It has native support for a wide variety of model flavors— think plain vanilla Sci-Kit Learn, but also models trained with R, SparkML, Tensorflow, Pytorch, amongst others.
Getting Started
Now that we know about experiment tracking, MLflow and why these are important in a Machine Learning project, let’s get started and see how it works in practice. We will:
- Create a free Databricks Workspace using Databricks Community Edition
- Create multiple runs for a machine learning experiment
- Compare these experiment runs
- Look at the artifacts that were generated by these runs
- Databricks Community Edition
The first step is signing up to Databricks Community Edition, a free version of the Databricks cloud based big data platform. It also comes with a rich portfolio of award-winning training resources that will be expanded over time, making it ideal for developers, data scientists, data engineers and other IT professionals to learn Apache Spark. On top of that, a managed installation of MLflow is also included.
Simply click on this link to get started. Once you register and login, you will be presented with your Databricks Workspace.
 2. Creating a compute cluster
2. Creating a compute cluster
In your workspace, you are able to create a small scale cluster for testing purposes. To do so, on the left hand side menu, click on the Compute button, and then on the Create Cluster button.
It is recommended to choose a runtime that supports ML applications natively — such runtime names end with LTS ML. By doing so, MLflow and other common machine learning frameworks will automatically be installed for you. Choose a name for your cluster and click create.
 3. Importing our Experiment Notebook
3. Importing our Experiment Notebook
Next, you will want to create a Databricks Notebook for training your model and tracking your experiments. To make things easier, you can import an existing quickstart notebook — but of course, if you prefer to write your own code to train your model, feel free to do so. The MLflow Quickstart Notebook used for this exercise can be found here.
In a nutshell, our quickstart notebook contains code to train a Machine Learning model to predict diabetes using a sample dataset from Sci-Kit Learn. The notebook is really well documented and contains all the details about the model and the different training steps.
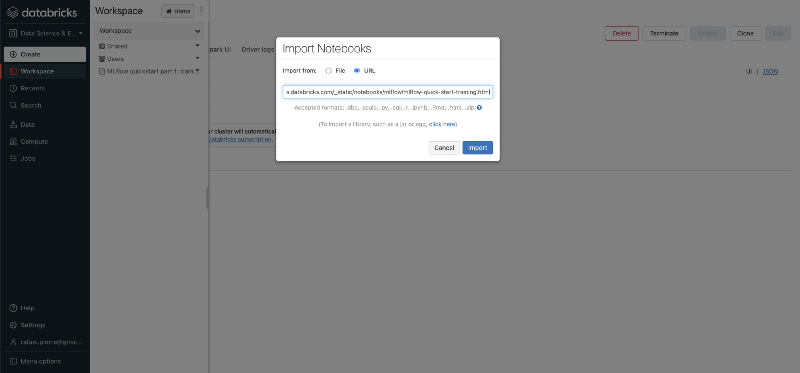 How to import an existing Databricks Notebook4. Running Your Notebook and Training Your Model
How to import an existing Databricks Notebook4. Running Your Notebook and Training Your Model
The next step is running your notebook and training your model. To do so, first attach the notebook to the cluster you have previously created, and click the Run All button.
If you are using our quickstart notebook, you will notice that each time you train your model with different parameters, a new experiment run will be logged on MLflow.
To have a quick glance on how each experiment run looks like, you can click on the experiments button at the top right of your notebook.
A more detailed view on your experiments is available on the Machine Learning UI.
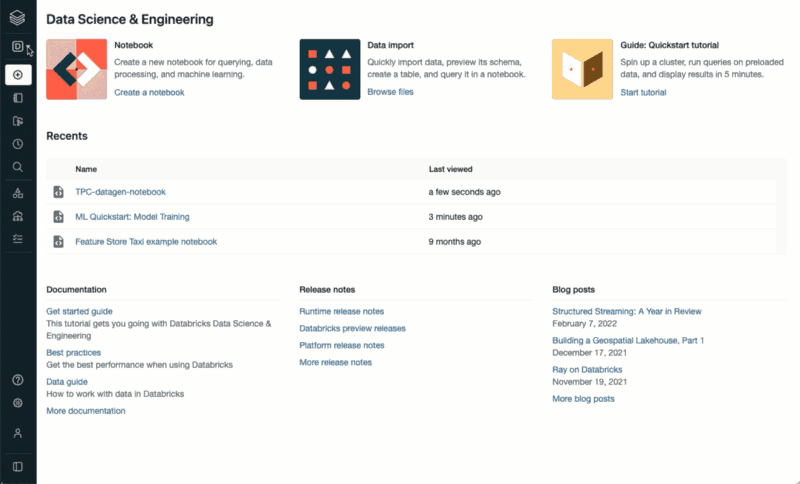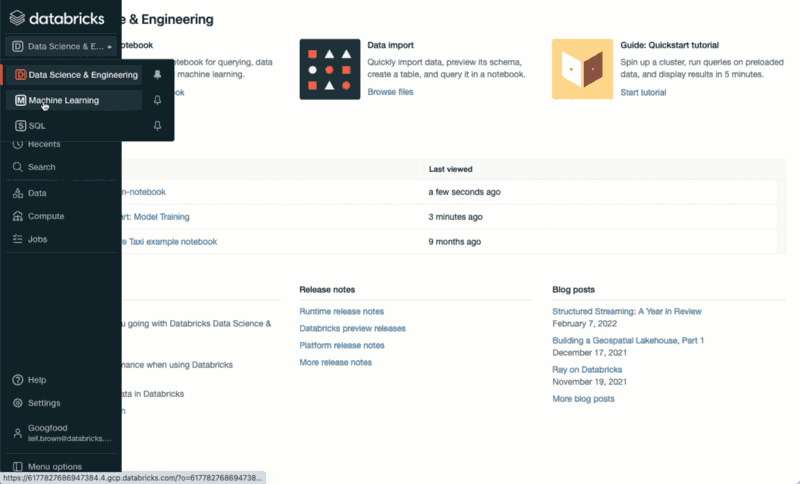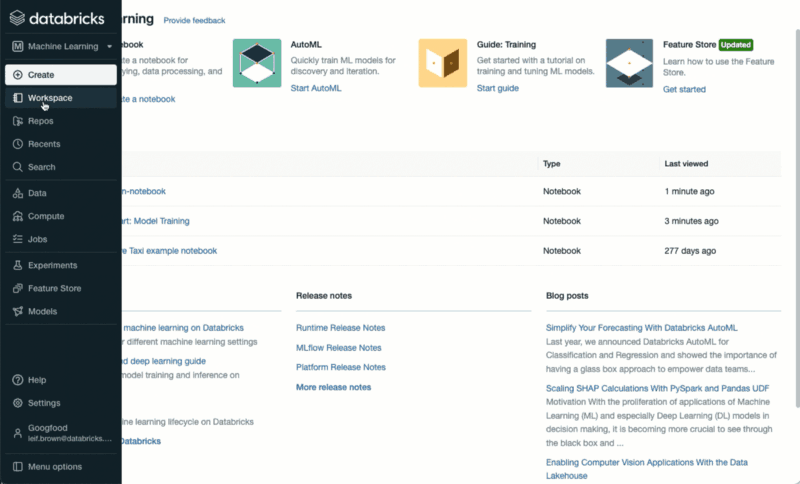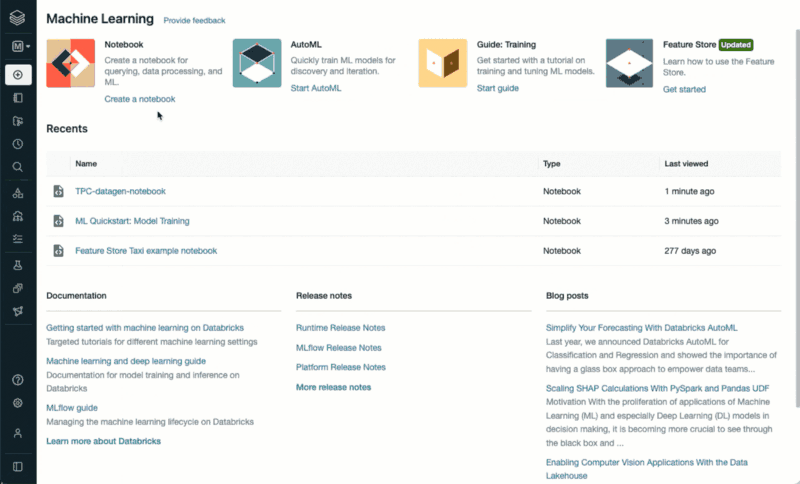 How to access the Databricks Machine Learning UIOnce you are on the Machine Learning UI, you can click on the Experiments button on the bottom of the left hand side menu. Doing so will display a detailed view of your different model runs.
How to access the Databricks Machine Learning UIOnce you are on the Machine Learning UI, you can click on the Experiments button on the bottom of the left hand side menu. Doing so will display a detailed view of your different model runs.
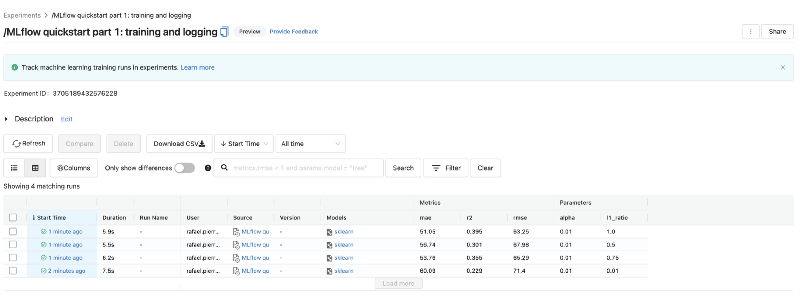 5. Comparing and Analysing Experiment Runs
5. Comparing and Analysing Experiment Runs
You can visually compare hyperparameters and metrics of different experiment runs. To do so, select the models you want to compare by clicking on their checkboxes on the left hand side of the main table, and click Compare.
By doing so, you will be able to inspect different hyperparameters that were used across experiment runs, and how they affect your model metrics. This is quite useful to understand how these parameters influence your model performance and conclude which set of parameters might be best — for deploying the final version of your model into production, or for continuing further experiments.
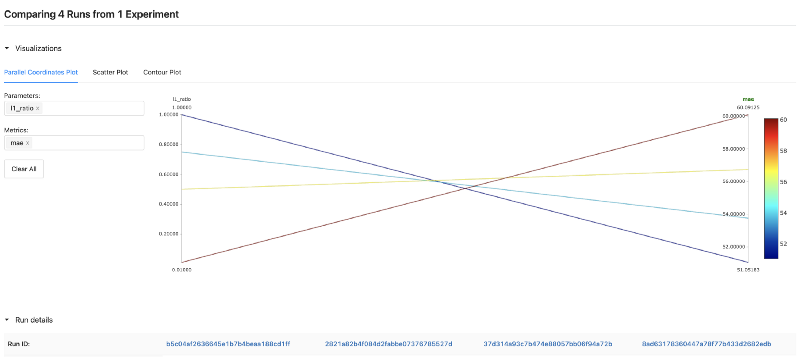 The great thing is that these results are available for you, but in a team setting, you could also share these with a wider team of Data Scientists, Data Engineers and Machine Learning Engineers.
The great thing is that these results are available for you, but in a team setting, you could also share these with a wider team of Data Scientists, Data Engineers and Machine Learning Engineers.
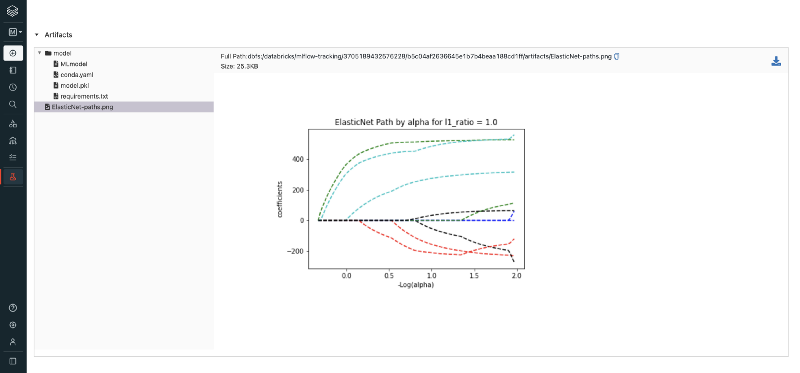
6. Model Artifacts
In our quickstart notebook, we have code for logging model parameters (mlflow.log_param), metrics (mlflow.log_metric) and models (mlflow.sklearn.log_model).
When you select a particular model from the table containing all experiment runs, you can see additional information related to that model, and also the artifacts related to that model.
This is also quite useful for when you want to deploy this model into production, since amongst the artifacts, you will have not only the serialized version of your model, but also a requirements.txt file containing a full list of Python environment dependencies for it.
 ### Main Takeaways
### Main Takeaways
By this point you should have understood:
- Why Machine Learning Experiment Tracking is critical for success when running production grade ML
- How MLflow makes it seamless to track Machine Learning experiments and centralize different model artifacts, enabling easy collaboration in ML teams
- How easy it is to train your models with Databricks and keep them on the right track with MLflow
There are some more important aspects to be covered, specially when we talk about model productionization and MLOps. But these will be the topic of a next post.
Further Reference
- Databricks Managed MLflow
- MLflow Quickstart
- MLflow Homepage
- MLflow Documentation
- What is MLOps?
- Machine Learning as an Experimental Science
You Might Also Like
Keeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 2
Learn how to use MLflow Model Registry to track, register and deploy Machine Learning Models effectively.mlopshowto.comWhat is Model Drift, and How it Can Negatively Affect Your Machine Learning Investment
In the domains of software engineering and mission critical systems, we cannot say that monitoring and instrumentation…mlopshowto.comWhat are Feature Stores and Why Are They Critical For Scaling Machine Learning
Understand why Feature Stores are critical for a good MLOps foundationmlopshowto.com