
Data Leakage, Part I: Think You Have a Great Machine Learning Model? Think Again
01 Oct 2018Got insanely excellent metric scores for your classification or regression model? Chances are you have data leakage.
 In this post, you will learn:
In this post, you will learn:
- What is data leakage
- How to detect it and
- How to avoid it
 You were presented with a challenging problem.
You were presented with a challenging problem.
As a driven, gritty, aspiring data scientist, you used all tools that were within your reach.
You gathered a reasonable amount of data. You have got a considerable amount of features. You were even able to come up with many additional features through feature engineering.
You used the fanciest possible machine learning model. You made sure your model didn’t overfit. You properly split your dataset in training and test sets.
You even used K-Folds validation.
You had been cracking your head for some time, and it seems that you finally had that “aha” moment.
 Chances are data leakage took on you.You were able to get an impressive 99% AUC (Area Under Curve) score for your classification problem. Your model has outstanding results when it comes to predicting labels for your testing set, properly detecting True Positives, True Negatives, False Positives and False Negatives.
Chances are data leakage took on you.You were able to get an impressive 99% AUC (Area Under Curve) score for your classification problem. Your model has outstanding results when it comes to predicting labels for your testing set, properly detecting True Positives, True Negatives, False Positives and False Negatives.
Or, in the case you had a regression problem, your model was able to get excellent MAE (Mean Absolute Error), MSE (Mean Squared Error) and R2 (Coefficient of Determination) scores.
Congratulations!
 Good job, you got zero error! NOT### Too Good to be True?
Good job, you got zero error! NOT### Too Good to be True?
 As a result of your efforts and the results you obtained, everyone at the office admires you. You have been lauded as the next machine learning genius.
As a result of your efforts and the results you obtained, everyone at the office admires you. You have been lauded as the next machine learning genius.
You can even picture yourself in your next vacation driving a convertible.
 But before that, it is time for showdown: your model is going into production.
But before that, it is time for showdown: your model is going into production.
However, when it’s finally time for your model to start doing some perfect predictions out on the wild, something weird happens.
 Your model is simply not good enough.
Your model is simply not good enough.
What is Data Leakage
 Data Leakage happens when for some reason, your model learns from data that wouldn’t (or shouldn’t) be available in a real-world scenario.
Data Leakage happens when for some reason, your model learns from data that wouldn’t (or shouldn’t) be available in a real-world scenario.
Or, in other words:
When the data you are using to train a machine learning algorithm happens to have the information you are trying to predict.
— Daniel Gutierrez, Ask a Data Scientist: Data Leakage
How to Detect Data Leakage
 Data Leakage happens a lot when we are dealing with data that has Time Series characteristics. That is, we have a series of data points that are distributed chronologically.
Data Leakage happens a lot when we are dealing with data that has Time Series characteristics. That is, we have a series of data points that are distributed chronologically.
One of the rules of thumb for trying to avoid Data Leakage for time series data is performing cross validation.
Cross validation involves randomly selecting data points from your dataset and assigning them to training and testing sets. Data preparation and feature engineering steps are done separately for the training and testing sets.
Nevertheless, depending on the nature of your dataset, you could have a target variable with a distribution that is similar for both training and testing sets.
In such case, it is easy for a model to learn that depending on the moment in time, probabilities for each target variable class change accordingly.
As a result, any feature from the dataset that has a relationship with time could potentially lead to data leakage.
How to Avoid Data Leakage
 There is no silver bullet for avoiding data leakage.
There is no silver bullet for avoiding data leakage.
It requires a change of mindset.
But the first step, in case you have a time-series dataset, is removing time-related features.
Remove Time-Related Features
 Time series analysis for Bitcoin prices.Typical forecasting problems, such as weather, cryptocurrencies and stock market price prediction require time series data analysis.
Time series analysis for Bitcoin prices.Typical forecasting problems, such as weather, cryptocurrencies and stock market price prediction require time series data analysis.
You might feel tempted to remove time-related features from your dataset. However, depending on the number of features in your dataset, this could prove to be a more complicated task, and you might end up removing features that could benefit your model.
On the other hand, incremental ID fields don’t add predictive power to your model and could cause data leakage. Hence most of the time it is recommended to remove them from your dataset.
But apart from that, tackling data leakage involves more of a mindset change when it comes to cross validation rather than feature selection.
Nested Cross-Validation
 Source: https://sebastianraschka.com/faq/docs/evaluate-a-model.htmlNested Cross Validation is the most appropriate method to evaluate performance when conceptualizing a predictive model for time-series data.
Source: https://sebastianraschka.com/faq/docs/evaluate-a-model.htmlNested Cross Validation is the most appropriate method to evaluate performance when conceptualizing a predictive model for time-series data.
One basic way of performing nested cross validation is predicting the second half. This involves the following steps:
- For a particular time-series dataset, select a point p in time
- All data points before p will be part of the training set
- All remaining data points after p will be part of the testing set
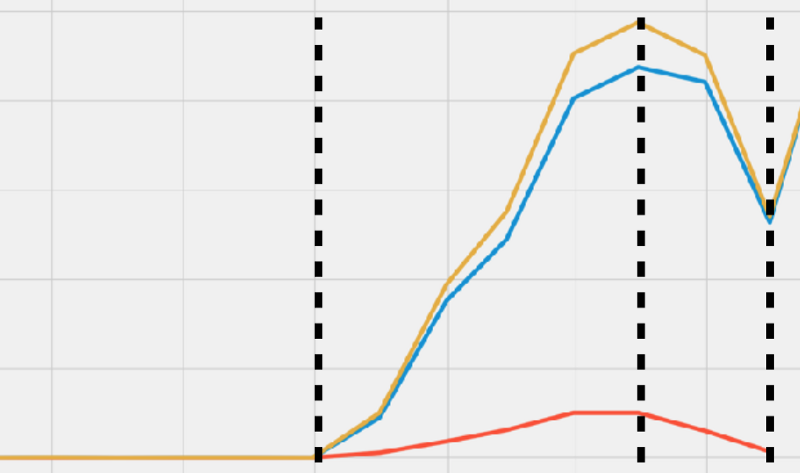 In this example, we perform the model training for the first portion of the dataset that is between the two dotted lines, and model testing for the second portion to the right.Predicting the second half is an easy and straightforward nested cross validation method for avoiding data leakage. It is also closer to the real-word, production scenario, but it comes with some caveats.
In this example, we perform the model training for the first portion of the dataset that is between the two dotted lines, and model testing for the second portion to the right.Predicting the second half is an easy and straightforward nested cross validation method for avoiding data leakage. It is also closer to the real-word, production scenario, but it comes with some caveats.
Depending on the splitting approach, bias could be introduced, and as a result, biased estimates of prediction error could be produced for an independent dataset.
This is where forward chaining comes to the rescue.
 Forward chaining involves creating many different folds within your dataset, in a way that you predict the second half for each of these folds.
Forward chaining involves creating many different folds within your dataset, in a way that you predict the second half for each of these folds.
This exposes the model to different points in time, thus mitigating bias. But this is subject for a next post.
In this article you learned:
- What is data leakage and why it could be a problem for you
- How to detect data leakage
- How to avoid data leakage — by removing time-related features and performing nested cross validation
You Might Also Like
Keeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 2
Learn how to use MLflow Model Registry to track, register and deploy Machine Learning Models effectively.mlopshowto.comKeeping Your Machine Learning Models on the Right Track: Getting Started with MLflow, Part 1
Learn why Model Tracking and MLflow are critical for a successful machine learning projectmlopshowto.comData Pipeline Orchestration on Steroids: Getting Started with Apache Airflow, Part 1
What is Apache Airflow?towardsdatascience.com